psi-exam und Zielkonflikte bei E-Prüfungen (Teil 1/4)
Artikelserie: KI und Datenschutz bei E-Prüfungen
Dies ist Teil 1 von 4 einer umfangreichen Artikelserie basierend auf meinem Vortrag beim Treffen der Datenschutzbeauftragten bayerischer Universitäten am 17.09.2025 an der Universität Bamberg.
In dieser Serie:
- Die Grundlagen – psi-exam und Zielkonflikte bei E-Prüfungen (dieser Artikel)
- KI im Praxiseinsatz – Chancen und Grenzen
- Kontrolle und Nachvollziehbarkeit – Die Screenshot-Lösung
- Zero-Trust-Vision – TEARS und Ausblick

Elektronische Prüfungen versprechen viel: effizientere Korrektur, bessere Gleichbehandlung, neue Möglichkeiten durch KI. In der Praxis kollidieren diese Versprechen aber mit harten Anforderungen an Datenschutz und Prüfungsrecht.
An der Universität Bamberg entwickeln wir seit 2022 ein E-Prüfungssystem. Wir können damit bis zu 340 Prüflinge in einem Raum gleichzeitig an Laptops prüfen. Aktuell wird das System in etwa zehn Modulen mit jährlich mehr als 600 Prüflingen genutzt.
Bei der Entwicklung und im Produktivbetrieb müssen wir immer wieder zwischen konkurrierenden Zielen abwägen. Mir sind zwei Zielkonflikte begegnet, die wir uns im Folgenden genauer ansehen werden.
Der erste Zielkonflikt ist: Datenschutz versus KI-Mehrwert. In jüngerer Vergangenheit kommen neue Innovationen auf die Prüfungslandschaft zu. Von allen Seiten wird der Wunsch herangetragen, die nächste technologische Innovation für das bessere Prüfen zu nutzen: große Sprachmodelle, meist einfach mit dem Sammelbegriff „KI“ bezeichnet – ChatGPT, Claude, Gemini oder ähnliches.
Manche Prüfende erwarten sich von KI-Werkzeugen für Prüfungen einen großen Mehrwert und kritisieren die datenschutzrechtlichen Hürden, die sie daran hindern, davon zu profitieren. Studierende wollen hingegen nicht, dass ihre Daten irgendwohin weitergegeben werden, worüber sie keine Kontrolle haben – aus gutem Grund, wie ich denke. Das schränkt uns als Prüfende ein. Die beeindruckenden Fähigkeiten von großen Sprachmodellen, die wir privat täglich nutzen, können wir in der Universität nicht verwenden.
Die größte Verlockung ist natürlich die automatische Korrektur –und dabei geht es nicht um Multiple-Choice-Aufgaben, da ist die automatisierte Auswertung ja schon lange üblich, sondern um Freitextantworten. Aber auch die Qualitätsverbesserung von Aufgabenstellungen könnte eine interessante Anwendung für KI-Werkzeuge sein.
Die entscheidende Frage: Gibt es irgendwo im Kontinuum zwischen „Alle Daten hergeben“ (maximaler KI-Nutzen) und „gar nichts damit machen“ Anwendungsfälle, die Nutzen stiften?

Nun zum zweiten Zielkonflikt: Anonymität versus Kontrolle. Studierende berichten mir immer wieder von Vorbehalten zur Neutralität der Prüfenden –gerade in anderen Fakultäten. In studentischen Gremien wird mitunter sogar der Vorwurf laut, dass nicht gerecht bewertet wird, sei es aufgrund von Herkunft, Geschlecht oder anderen persönlichen Eigenschaften.
Der Wunsch nach einer anonymen Korrektur von Prüfungen ist daher nachvollziehbar. Dass es bei nicht-anonymer Bewertung zu beabsichtigten und unbeabsichtigten Verzerrungen kommen kann, wurde meines Wissens auch in Studien schon nachgewiesen. Prüfungsämter winken bei diesem Thema aber schnell ab: „Das ist unmöglich – unsere Prozesse basieren auf Namen und Matrikelnummern.“
Gleichzeitig brauchen wir aber auch das Gegenteil von Anonymität – Nachvollziehbarkeit und Kontrolle, nämlich um Täuschungsversuche zu verhindern.
Der zweite Zielkonflikt hat also mehrere Facetten:
- Eine faire Bewertung braucht pseudonyme oder besser noch eine vollständig anonyme Korrektur.
- Für Rechtssicherheit brauchten wir Täuschungskontrolle und Beweissicherung.
- Und dann gibt es noch ein weiteres Problem: das Mächte-Ungleichgewicht zwischen Universität und Studierenden. Die Universität gibt die Spielregeln vor und stellt die Technik. Die Studierenden sind dem weitgehend ausgeliefert, haben kaum Einflussmöglichkeiten und wenig Einblick. Schwer zu akzeptieren.
Bevor ich zeige, wie wir diese Konflikte angehen, folgende Einschränkung: Der Fokus liegt im Folgenden ausschließlich auf schriftlichen E-Prüfungen unter Aufsicht.
Hausarbeiten haben wir angesichts der großen Qualitätsunterschiede kostenloser und kommerzieller KI-Werkzeuge fürs Erste faktisch aufgegeben –die Chancengleichheit ist nicht mehr gewährleistbar. Und KI-Detektoren? Eine intransparente Blackbox mit Fehlerquoten, auf die wir keine Prüfungsentscheidungen stützen wollen.
psi-exam: Datenschutzfreundliche E-Prüfungen
Wir schauen uns nun kurz unser System psi-exam an und wie es bereits ohne KI erhebliche Vorteile gegenüber herkömmlichen Klausuren bietet.
Besuchen Sie die psi-exam-Webseite, die weitere Details zum System sowie ein Einführungsvideo bietet, das wir unseren Studierenden zeigen.
psi-exam ist ein browserbasiertes Prüfungssystem für bis zu 350 Studierende gleichzeitig. Wir haben etwa 380 Linux-Laptops, die wir im Prüfungsraum der Universität schnell auf- und abbauen können –für dedizierte E-Prüfungsräume ist an unserer Universität weder Platz noch Geld.
Studierende bearbeiten Aufgaben in Formularfeldern im Browser. Die Kontrolle der Identität findet während der Prüfung am Sitzplatz statt, sodass wir wissen: Maria Müller saß auf Platz 37, und ihr Ausweis bestätigt ihre Identität.
Nach dem Ende der Prüfung werden alle Antworten verschlüsselt hochgeladen. Aber –und hier wird es interessant –der Server sieht nur Chiffretext. Die Schlüssel liegen ausschließlich bei der bzw. dem E-Prüfungsorganisierenden.
Diese Person erzeugt für die Prüfenden einen Einladungslink mit einem speziellen Schlüssel. Der Clou: Bei der Erzeugung entscheidet die bzw. der Organisierende, ob dieser Schlüssel Klarnamen oder nur Pseudonyme anzeigt. Anstelle der Namen der Studierenden werden dann Tiernamen angezeigt, etwa „Brave Elk“, „Clever Jaguar“ und „Curious Panda“.
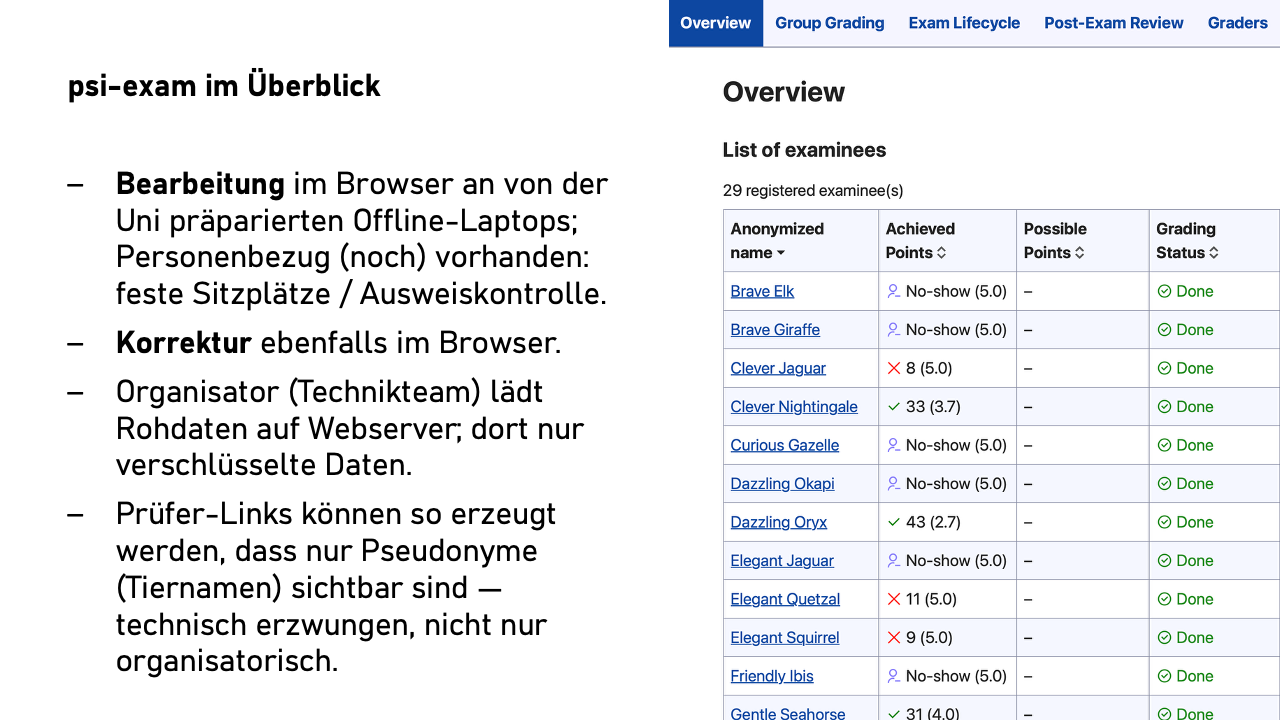
Das Entscheidende: Die Prüfenden haben nicht die Möglichkeit, die echten Namen zu sehen – Pseudonymität ist keine Frage von Disziplin oder Vertrauen, sondern technisch erzwungen.
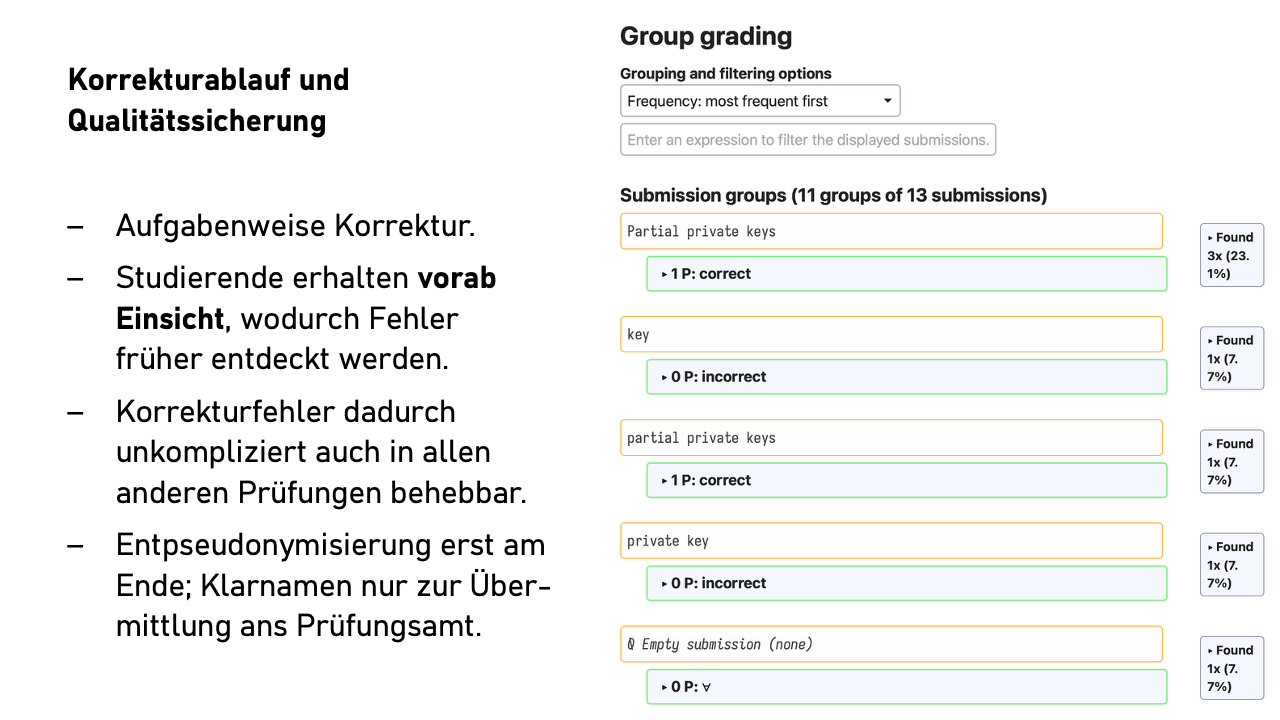
Die Korrektur erfolgt aufgabenweise. Also erst alle Antworten zu Aufgabe 1a, dann 1b, und so weiter. Die Reihenfolge ist konfigurierbar: nach Antwortlänge, alphabetisch nach erstem Wort der Antwort, aber natürlich nicht nach Personenname. Wir reden hier wohlgemerkt von Freitextantworten, nicht von Multiple-Choice-Aufgaben.
Wenn wir jetzt erst in der Einsicht einen systematischen Korrekturfehler feststellen, beheben wir den Fehler auch gleich in allen anderen betroffenen Prüfungen – bei Papierklausuren undenkbar.
Das hat zwei Effekte: Erstens spart es mentale Energie durch den gleichbleibenden Kontext zwischen aufeinanderfolgenden Antworten. Zweitens landen ähnliche oder identische Antworten direkt nacheinander. Wenn zwanzig Studierende identisch oder fast identisch antworten, lässt sich das schnell und konsistent bewerten.
Man kann auch nach Stichwörtern filtern oder bei Ja/Nein-Fragen mit Begründung alle „Ja“-Antworten zusammen korrigieren. Das erhöht den Komfortfaktor erheblich, ohne datenschutzrelevante Auswirkungen.
Prüfende können weitere Einladungslinks erzeugen –für Tutorinnen und Tutoren zur Vorkorrektur oder für die Zweitprüfenden. Auch diese Links können pseudonym konfiguriert werden. Die Zweitprüfenden sehen nur die Durchgefallenen, können die Erstbewertung einsehen und kommentieren.
Das System arbeitet dabei datensparsam: Wir speichern keine personenbezogenen Daten über Prüfende oder Zweitprüfende. Prüfende haben im System Städtenamen. Die bzw. der Organisierende kennt nur die Identität der Erstprüfenden, aber nicht, wen die Erstprüfenden zur Korrektur oder Zweitkorrektur eingeladen haben.
Einsicht schon vor Notenbekanntgabe. Hier weichen wir radikal vom üblichen Prozess ab. Direkt nach der Erstkorrektur –noch vor der Zweitkorrektur und noch lange vor der Übermittlung der Noten ans Prüfungsamt –bekommen Studierende individuelle Einsichtslinks. Sie sehen ihre Antworten, die Bewertung und eine Musterlösung.
Das verändert die Dynamik komplett: Der Aufwand für die Einsichtnahme ist viel geringer als bei Papierklausuren. Außerdem ist es für die Studierenden eine angenehmere Situation. Sie kommunizieren direkt mit den Erstprüfenden, nicht mit dem – möglicherweise abschreckenden – Prüfungsamt. Sie haben einen starken persönlichen Anreiz, genau hinzuschauen und können oft besser als fachfremde Zweitprüfende beurteilen, ob ihre alternative Interpretation einer Aufgabe nicht vielleicht doch eine valide Antwort ist.
Wenn eine Studentin oder ein Student eine überzeugende Argumentation liefert –vielleicht aufgrund einer uneindeutigen Aufgabenstellung -, können wir reagieren. Und hier kommt der eigentliche Vorteil digitaler Prüfungen zum Tragen: Mit einem Klick können wir dann alle 350 Prüfungen nach ähnlichen Antworten durchsuchen und die Punkte überall anpassen.
Auf Papier würde niemand den ganzen Stapel vom Prüfungsamt anfordern, nur weil eine Prüfung nach der Einsicht zwei Punkte mehr bekommen hat. Digital kostet uns das fast nichts – und wir müssen ja schließlich alle gleich behandeln.
Am Ende des Prozesses wird die Pseudonymisierung aufgehoben. Entweder die bzw. der Organisierende übernimmt das (sie bzw. er hat ja die ursprünglichen Daten von den Laptops), oder sie bzw. er schickt den Prüfenden nach Abschluss der Korrektur einen neuen Link, der die Klarnamen anzeigt.
Was haben wir bis hierher erreicht? Ich habe unser System psi-exam vorgestellt, das eine pseudonyme Korrektur technisch erzwingt, dabei aber flexibel genug für die Realität des Prüfungsbetriebs bleibt. Datensparsamkeit ist eingebaut, nicht draufgesetzt. Die Gleichbehandlung ist durch die aufgabenweise Korrektur und die nachträgliche Anpassungsmöglichkeit besser als bei Papierklausuren.
Aber wir haben bisher nur die eine Seite unserer Zielkonflikte adressiert. Was ist mit KI? Wie können Prüfende von KI-Werkzeugen profitieren? Und wie sieht es dort mit der Datensparsamkeit aus?
Kurz gesagt – Teil 1
psi-exam zeigt: Datenschutzfreundliche E-Prüfungen sind möglich – mit technisch erzwungener Pseudonymität, aufgabenweiser Korrektur und verbesserter Gleichbehandlung gegenüber Papierklausuren.
Die Zielkonflikte bleiben: Datenschutz vs. KI-Mehrwert sowie Anonymität vs. Kontrolle prägen die weitere Entwicklung.
Der Weg ist das Ziel: Datensparsamkeit muss nicht aufgesetzt werden, sie kann technisch eingebaut sein.
Im nächsten Teil der Serie betrachten wir, wie KI-Werkzeuge konkret bei E-Prüfungen eingesetzt werden können – und wo die Grenzen liegen. Spoiler: Die automatische Korrektur ist nicht das, was Sie erwarten.
Aus der Diskussion
Aufgabentypen und Einschränkungen
Frage: Welche Aufgabentypen funktionieren nicht gut elektronisch?
Antwort: Zeichnungen, Skizzen, mathematische Herleitungen mit vielen Symbolen sind schwierig. Pragmatische Lösung: Diese Teile weiterhin auf Papier, dann scannen und mit elektronischen Teilen zusammenführen. Alternative: Vorbereitete Diagramme zum Annotieren.
Dokumentation und Compliance
Nachfragen zur Datenschutz-Dokumentation: Das bisherige System hat:
- Grundlegende Prozessdokumentation
- Art. 13 DSGVO-Informationen für alle Beteiligten
- Checklisten für Prüfungsdurchführung
- Archivierungskonzept mit Löschfristen
Noch fehlend: Formales Verfahrensverzeichnis (wird bei Bedarf erstellt). Einschätzung im Raum: Die technische Dokumentation zusammen mit Datenschutz-Grundüberlegungen erfüllt die Dokumentationsanforderungen zumindest grundlegend.
Institutionelle Herausforderungen
Realität: Das System läuft aktuell als „funktionsfähiger Prototyp“ am Lehrstuhl, in den nächsten Jahren noch durch Drittmittel finanziert, nicht als Universitätsservice. Überführung in regulären Betrieb wird erfordern:
- Ertüchtigung der technischen Umsetzung für Regelbetrieb
- Dediziertes Personal, Schulungen bestehenden Verwaltungspersonals
- Umfangreichere Dokumentation
- Politischer Wille und Finanzierung
Pragmatismus: „Best Effort“ - es funktioniert, tausende Prüfungen sind durchgelaufen, im Rahmen des Projekts BaKuLe wird die Überführung in den Regelbetrieb ausgelotet und durchgeführt.